Runtime Environment scaling
The runtime environment's compute resources mainly include Worker node resources, Proxy node resources, and Controller node resources. When your cluster resource utilization is high or the load is heavy, you can scale the cluster based on the following dimensions.
Adjusting Worker Node Instance Quantity
Cache instances are deployed on worker nodes. When worker node load is high or memory usage is high, you can increase the number of worker node instances.
- Log in to the Montplex console, select Runtime, and enter the Montplex Kubernetes Clusters list page.
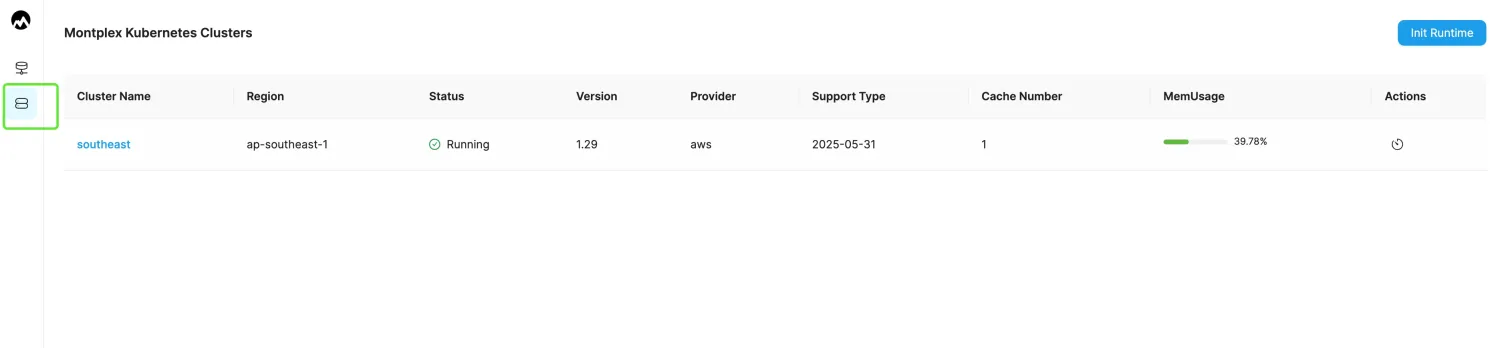
- Select the cluster name to enter the cluster details page.
- Choose the Node Groups tab, then select Worker.
- In the Worker node where you need to adjust the number of instances, click the scale in/out graphic button in the Action column.
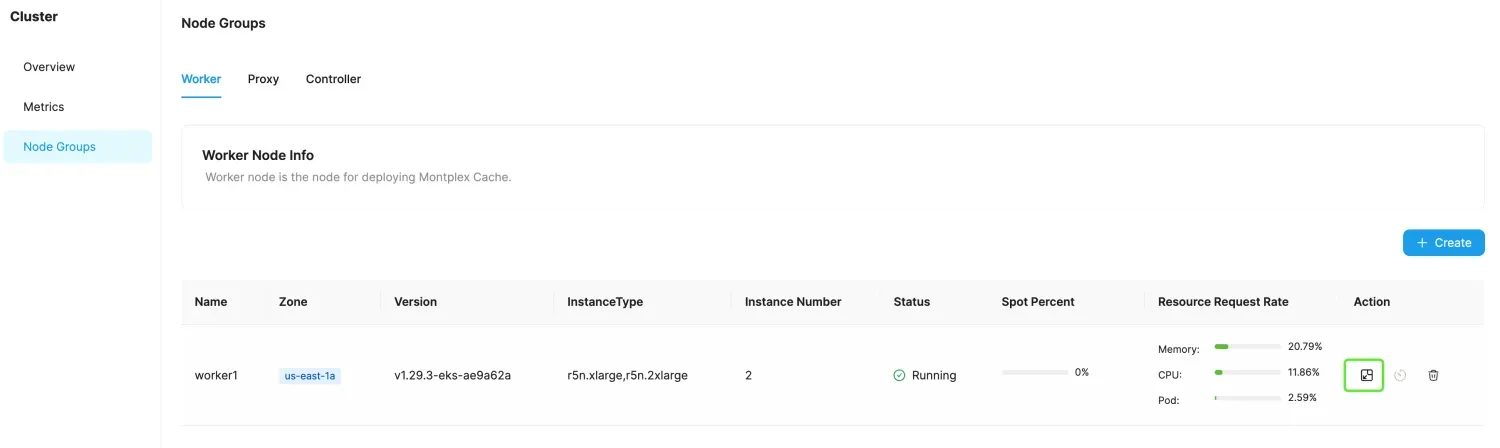
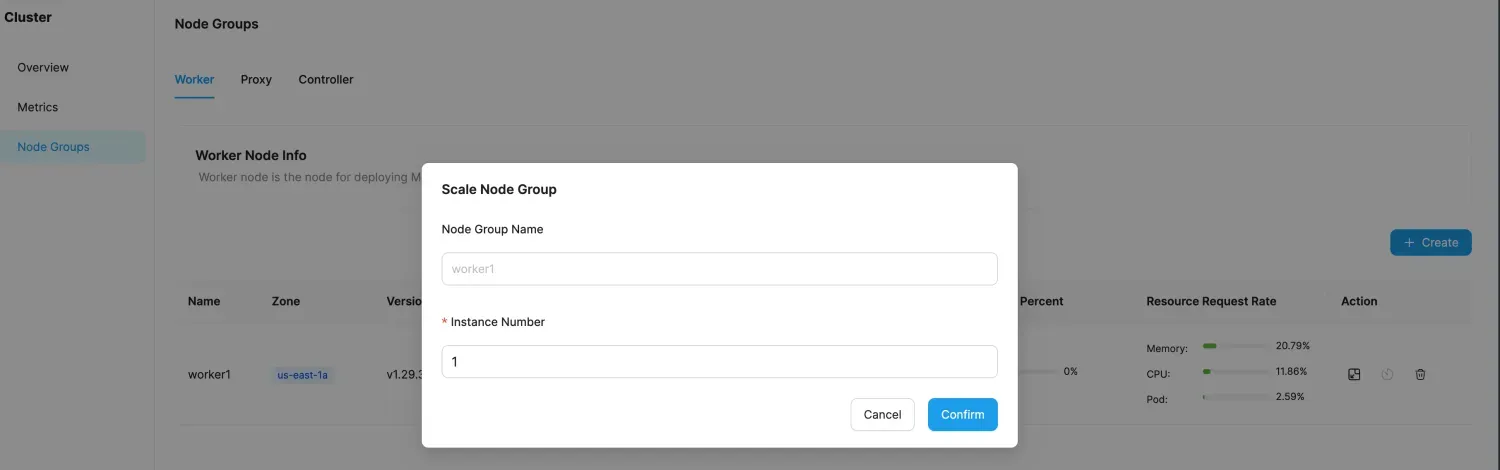
- Modify the target number of instances.
- Confirm the scaling operation. The scale-out operation requires launching new EC2 instances, which typically takes about 3 minutes. Scaling in requires migrating the Cache's data, and the time depends on the amount of cached data.
Adjusting Controller Node Instance Quantity
Montplex Control components are deployed on the Controller node group. When the Controller node's load is high or memory usage is high, you can expand the number of instances in the Controller node group.
- Log in to the Montplex console, select Runtime, and enter the Montplex Kubernetes Clusters list page.
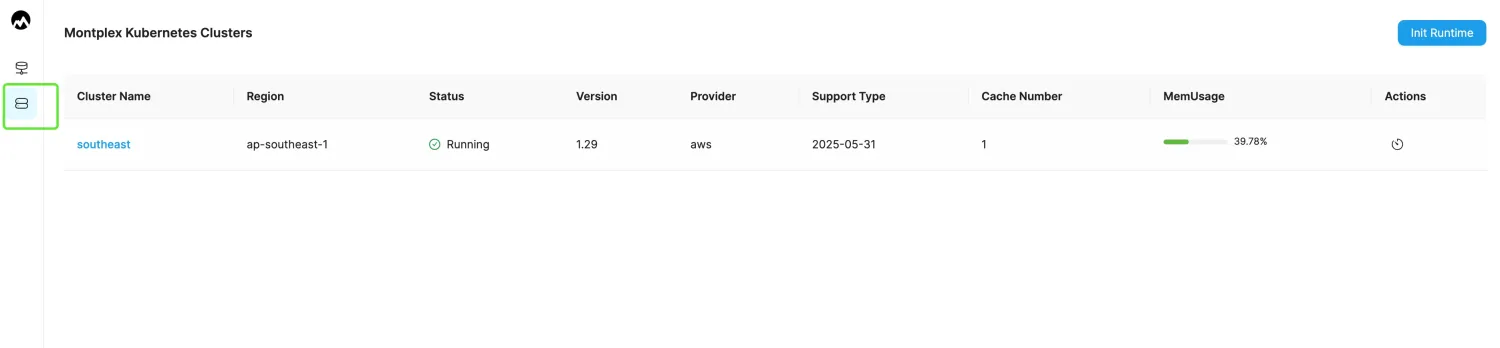
- Select the cluster name to enter the cluster details page.
- Choose the Node Groups tab, then select Controller.
- Click the scale in/out graphic button labeled "Scale".
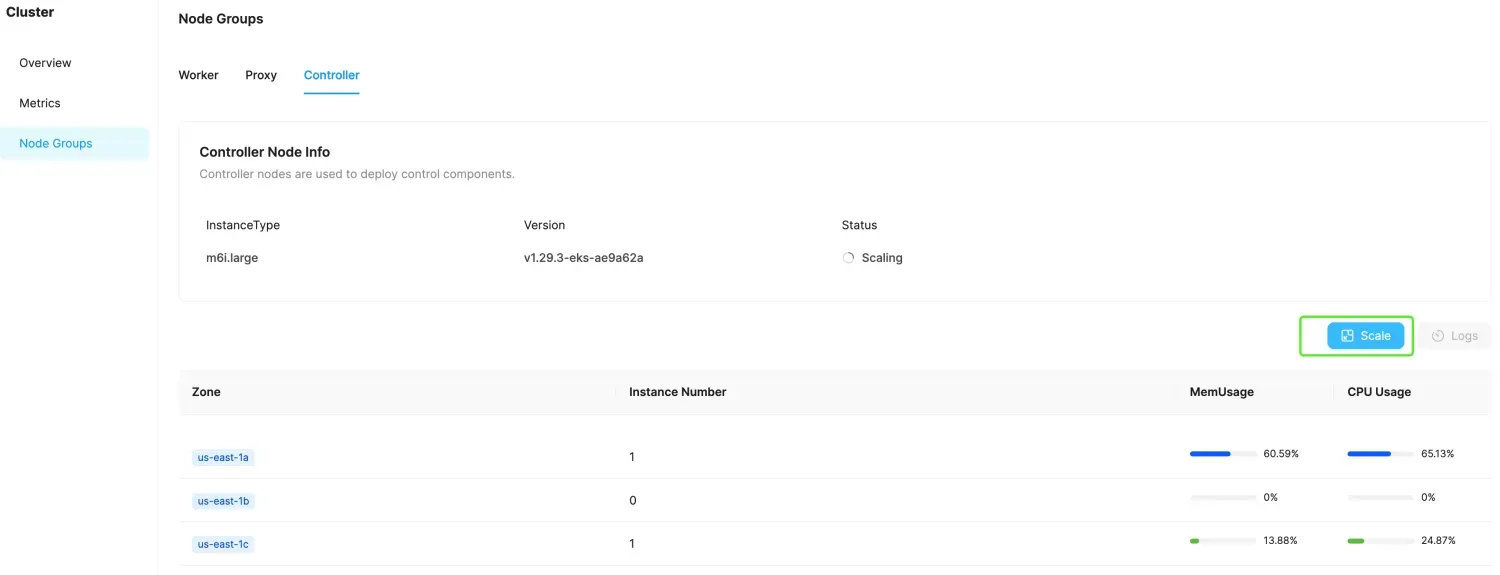
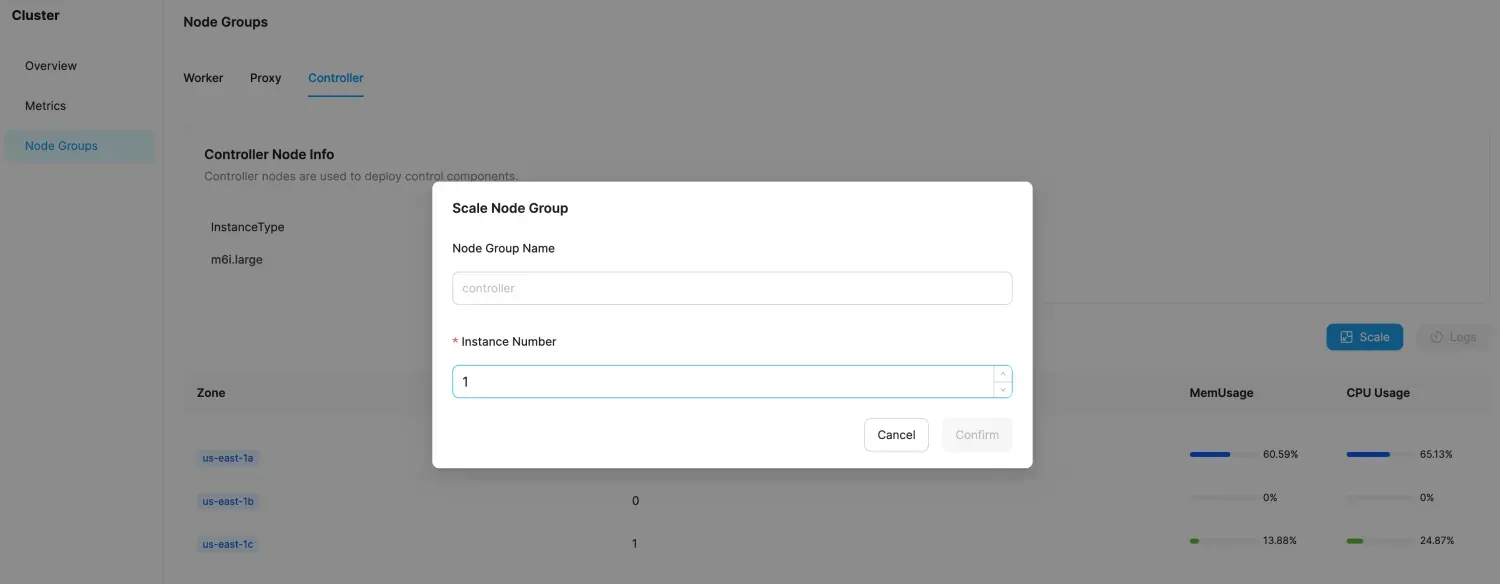
- Modify the target number of instances.
- Confirm the scaling operation. The scale-out operation requires launching new EC2 instances, which typically takes about 3 minutes. Scaling in requires evicting business control services, which normally takes about 2-5 minutes. In total, the process takes approximately 5-8 minutes.
Adjusting Proxy Nodes
The Proxy component is deployed in the Proxy node group. The Proxy node group uses mixed instance deployment (On-Demand and Spot instances), with a default configuration of running up to 50% Spot instances.
Proxy Component Replicas
The Proxy component uses HPA (Horizontal Pod Autoscaler) to monitor CPU resource utilization. It automatically scales elastically based on resource usage, adjusting the number of Proxy component replicas.
Number of Proxy Nodes
As the number of Proxy component replicas increases or decreases, the resource utilization of the Proxy node group will also increase or decrease. When the Proxy node group's resources are nearly exhausted, the cluster will activate the automatic scaling service for Proxy nodes, increasing the number of nodes in the Proxy group. When the Proxy node group's resources are excessive, the cluster will activate the automatic scaling-in service for Proxy nodes, reducing the number of nodes in the Proxy group.
Adding Worker Node Availability Zones
When there is a business need to deploy in a new, previously unused availability zone, you can add a Worker node group for the new availability zone.
- Log in to the Montplex console, select Runtime, and enter the Montplex Kubernetes Clusters list page.
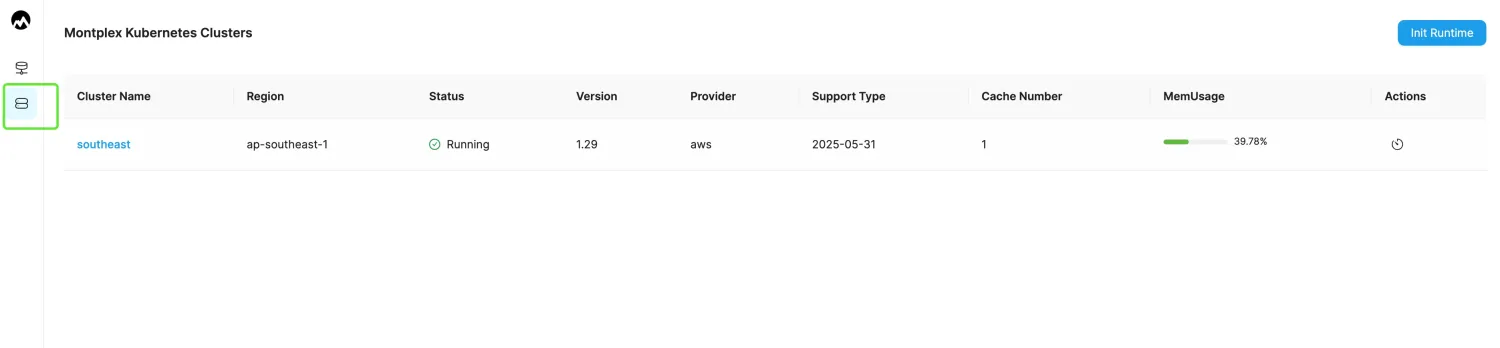
- Select the cluster name to enter the cluster details page.
- Select the Node Groups tab, then select Worker.
- Choose Create to create a new Node Group.
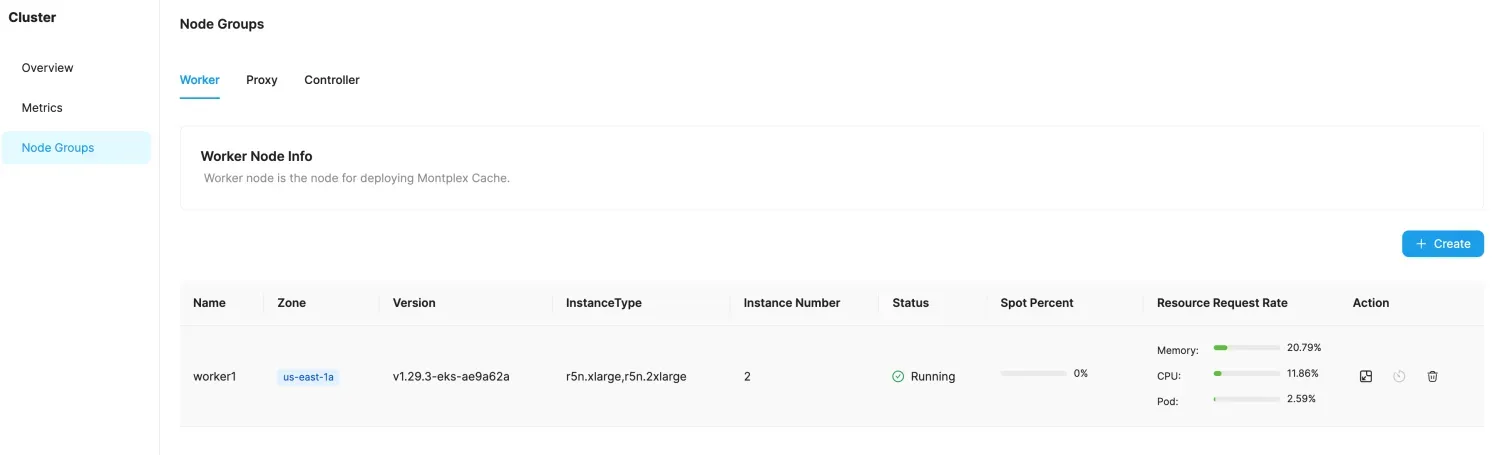
- Select the name, availability zone, and number of instances for the new Node Group.
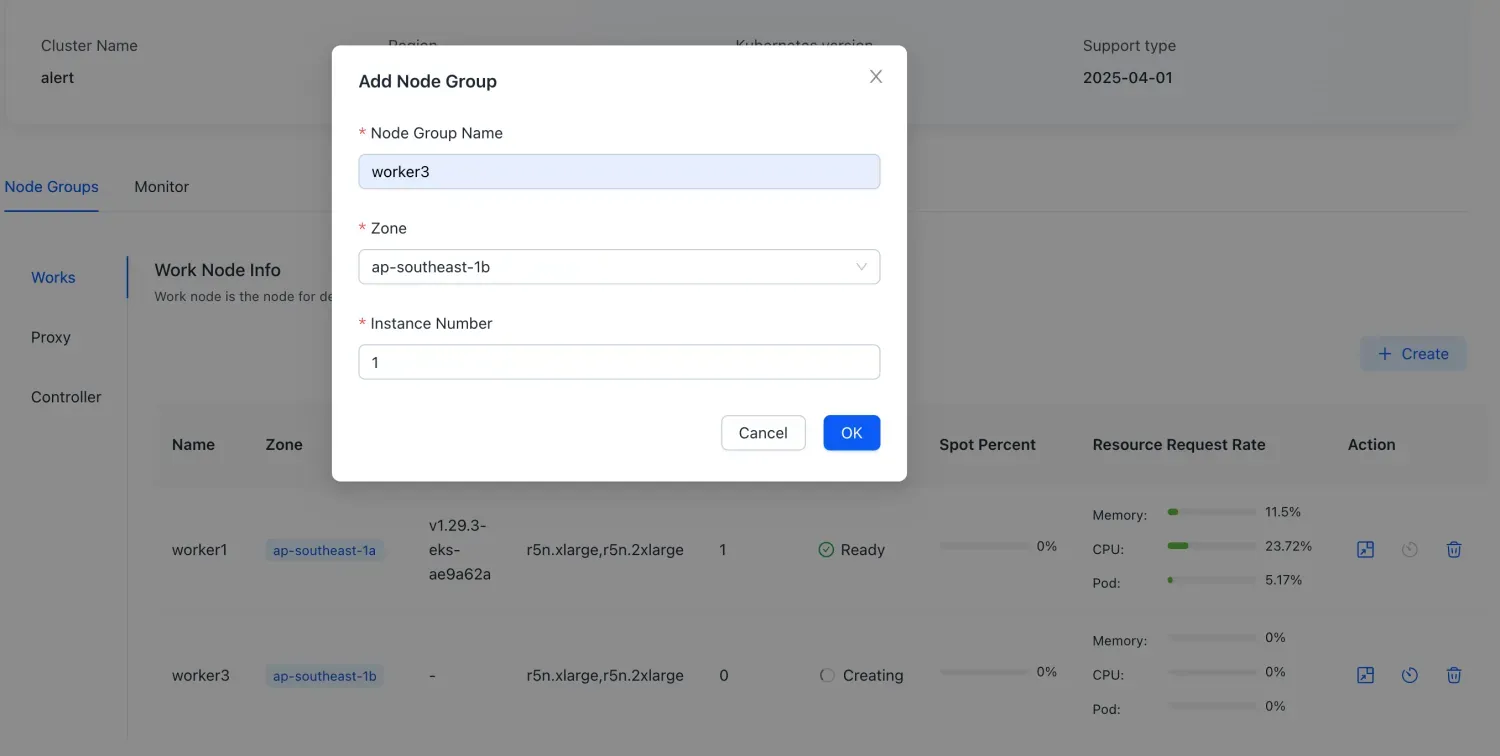
- Execute the creation process.
This process will launch the specified number of EC2 instances in the new availability zone and add them to the cluster. If the VPC doesn't have enough available subnets, the creation will fail. This process is expected to take about 3-5 minutes.